5.3 设计与演化
其实讲一个东西,讲它是什么样是不足够的。如果能讲清楚它为什么会是这样子,则会举一反三。为了理解goroutine的本质,这里将从最基本的线程池讲起,谈谈Go调度设计背后的故事,讲清楚它为什么是这样子。
线程池
先看一些简单点的吧。一个常规的 线程池+任务队列 的模型如图所示:
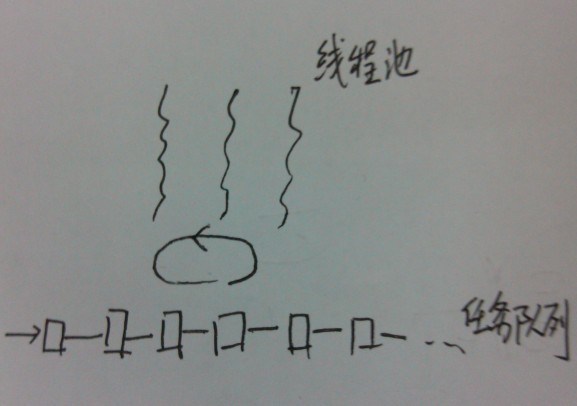
把每个工作线程叫worker的话,每条线程运行一个worker,每个worker做的事情就是不停地从队列中取出任务并执行:
while(!empty(queue)) {
q = get(queue); //从任务队列中取一个(涉及加锁等)
q->callback(); //执行该任务
}
当然,这是最简单的情形,但是一个很明显的问题就是一个进入callback之后,就失去了控制权。因为没有一个调度器层的东西,一个任务可以执行很长很长时间一直占用的worker线程,或者阻塞于io之类的。
也许用Go语言表述会更地道一些。好吧,那么让我们用Go语言来描述。假设我们有一些“任务”,任务是一个可运行的东西,也就是只要满足Run函数,它就是一个任务。所以我们就把这个任务叫作接口G吧。
type G interface {
Run()
}
我们有一个全局的任务队列,里面包含很多可运行的任务。线程池的各个线程从全局的任务队列中取任务时,显然是需要并发保护的,所以有下面这个结构体:
type Sched struct {
allg []G
lock *sync.Mutex
}
以及它的变量
var sched Sched
每条线程是一个worker,这里我们给worker换个名字,就把它叫M吧。前面已经说过了,worker做的事情就是不停的去任务队列中取一个任务出来执行。于是用Go语言大概可以写成这样子:
func M() {
for {
sched.lock.Lock() //互斥地从就绪G队列中取一个g出来运行
if sched.allg > 0 {
g := sched.allg[0]
sched.allg = sched.allg[1:]
sched.lock.Unlock()
g.Run() //运行它
} else {
sched.lock.Unlock()
}
}
}
接下来,将整个系统启动:
for i:=0; i<GOMAXPROCS; i++ {
go M()
}
假定我们有一个满足G接口的main,然后它在自己的Run中不断地将新的任务挂到sched.allg中,这个线程池+任务队列的系统模型就会一直运行下去。
可以看到,这里在代码取中故意地用Go语言中的G,M,甚至包括GOMAXPROCS等取名字。其实本质上,Go语言的调度层无非就是这样一个工作模式的:几条物理线程,不停地取goroutine运行。
系统调用
上面的情形太简单了,就是工作线程不停地取goroutine运行,这个还不能称之为调度。调度之所以为调度,是因为有一些复杂的控制机制,比如哪个goroutine应该被运行,它应该运行多久,什么时候将它换出来。用前面的代码来说明Go的调度会有一些小问题。Run函数会一直执行,在它结束之前不会返回到调用器层面。那么假设上面的任务中Run进入到一个阻塞的系统调用了,那么M也就跟着一起阻塞了,实际工作的线程就少了一个,无法充分利用CPU。
一个简单的解决办法是在进入系统调用之前再制造一个M出来干活,这样就填补了这个进入系统调用的M的空缺,始终保证有GOMAXPROCS个工作线程在干活了。
func entersyscall() {
go M()
}
那么出系统调用时怎么办呢?如果让M接着干活,岂不超过了GOMAXPROCS个线程了?所以这个M不能再干活了,要限制干活的M个数为GOMAXPROCS个,多了则让它们闲置(物理线程比CPU多很多就没意义了,让它们相互抢CPU反而会降低利用率)。
func exitsyscall() {
if len(allm) >= GOMAXPROCS {
sched.lock.Lock()
sched.allg = append(sched.allg, g) //把g放回到队列中
sched.lock.Unlock()
time.Sleep() //这个M不再干活
}
}
于是就变成了这样子:
其实这个也很好理解,就像线程池做负载调节一样,当任务队列很长后,忙不过来了,则再开几条线程出来。而如果任务队列为空了,则可以释放一些线程。
协程与保存上下文
大家都知道阻塞于系统调用,会白白浪费CPU。而使用异步事件或回调的思维方式又十分反人类。上面的模型既然这么简单明了,为什么不这么用呢?其实上面的东西看上去简单,但实现起来确不那么容易。
将一个正在执行的任务yield出去,再在某个时刻再弄回来继续运行,这就涉及到一个麻烦的问题,即保存和恢复运行时的上下文环境。
在此先引入协程的概念。协程是轻量级的线程,它相对线程的优势就在于协程非常轻量级,进行切换以及保存上下文环境代价非常的小。协程的具体的实现方式有多种,上面就是其中一种基于线程池的实现方式。每个协程是一个任务,可以保存和恢复任务运行时的上下文环境。
协程一类的东西一般会提供类似yield的函数。协程运行到一定时候就主动调用yield放弃自己的执行,把自己再次放回到任务队列中等待下一次调用时机等等。
其实Go语言中的goroutine就是协程。每个结构体G中有一个sched域就是用于保存自己上下文的。这样,这种goroutine就可以被换出去,再换进来。这种上下文保存在用户态完成,不必陷入到内核,非常的轻量,速度很快。保存的信息很少,只有当前的PC,SP等少量信息。只是由于要优化,所以代码看上去更复杂一些,比如要重用内存空间所以会有gfree和mhead之类的东西。
Go1.0
在前面的代码中,线程与M是直接对应的关系,这个解耦还是不够。Go1.0中将M抽出来成为了一个结构体,startm函数是线程的入口地址,而goroutine的入口地址是go表达式中的那个函数。总体上跟上面的结构差不多,进出系统调用的时候goroutine会跟M一起进入到系统调用中,schedule中会匹配g和m,让空闲的m来运行g。如果检测到干活的数量少于GOMAXPROCS并且没有空闲着的m,则会创建新的m来运行g。出系统调用的时候,如果已经有GOMAXPROCS个m在干活了,则这个出系统调用的m会被挂起,它的g也会被挂到待运行的goroutine队列中。
在Go语言中m是machine的缩写,也就是机器的抽象。它被设计成了可以运行所有的G。比如说一个g开始在某个m上运行,经过几次进出系统调用之后,可能运行它的m挂起了,其它的m会将它从队列中取出并继续运行。
每次调度都会涉及对g和m等队列的操作,这些全局的数据在多线程情况下使用就会涉及到大量的锁操作。在频繁的系统调用中这将是一个很大的开销。为了减少系统调用开销,Go1.0在这里做了一些优化的。1.0版中,在它的Sched结构体中有一个atomic字段,类型是一个volatile的无符32位整型。
// sched中的原子字段是一个原子的uint32,存放下列域
// 15位 mcpu --正在占用cpu运行的m数量 (进入syscall的m是不占用cpu的)
// 15位 mcpumax --最大允许这么多个m同时使用cpu
// 1位 waitstop --有g等待结束
// 1位 gwaiting --等待队列不为空,有g处于waiting状态
// [15 bits] mcpu number of m's executing on cpu
// [15 bits] mcpumax max number of m's allowed on cpu
// [1 bit] waitstop some g is waiting on stopped
// [1 bit] gwaiting gwait != 0
这些信息是进行系统调用和出系统调用时需要用到的,它会决定是否需要进入到调度器层面。直接用CAS操作Sched的atomic字段判断,将它们打包成一个字节使得可以通过一次原子读写获取它们而不用加锁。这将极大的减少那些大量使用系统调用或者cgo的多线程程序的contention。
除了进出系统调用以外,操作这些域只会发生于持有调度器锁的时候,因此goroutines不用担心其它goroutine会对这些字段进行操作。特别是,进出系统调用只会读mcpumax,waitstop和gwaiting。决不会写他们。因此,(持有调度器锁)写这些域时完全不用担心会发生写冲突。
总体上看,Go1.0调度设计结构比较简单,代码也比较清晰。但是也存在一些问题。这样的调度器设计限制了Go程序的并发度。测试发现有14%是的时间浪费在了runtime.futex()中。
具体地看:
- 单个全局锁(Sched.Lock)用来保护所有的goroutine相关的操作(创建,完成,调度等)。
- Goroutine切换。工作线程在各自之前切换goroutine,这导致延迟和额外的负担。每个M都必须可以执行任何的G.
- 内存缓存MCache是每个M的。而当M阻塞后,相应的内存资源也被一起拿走了。
- 过多的线程阻塞、恢复。系统调用时的工作线程会频繁地阻塞,恢复,造成过多的负担。
第一点很明显,所有的goroutine都用一个锁保护的,这个锁粒度是比较大的,只要goroutine的相关操作都会锁住调度。然后是goroutine切换,前面说了,每个M都是可以执行所有的goroutine的。举个很简单的类比,多核CPU中每个核都去执行不同线程的代码,这显然是不利于缓存的局部性的,切换开销也会变大。内存缓存和其它缓存是关联到所有的M的,而事实上它本只需要关联到运行Go代码的M(阻塞于系统调用的M是不需要mcache的)。运行着Go代码的M和所有M的比例可能高达1:100。这导致过度的资源消耗。
Go1.1
Go1.1相对于1.0一个重要的改动就是重新调用了调度器。前面已经看到,老版本中的调度器实现是存在一些问题的。解决方式是引入Processor的概念,并在Processors之上实现工作流窃取的调度器。
M代表OS线程。P代表Go代码执行时需要的资源。当M执行Go代码时,它需要关联一个P,当M为idle或者在系统调用中时,它也需要P。有刚好GOMAXPROCS个P。所有的P被组织为一个数组,工作流窃取需要这个条件。GOMAXPROCS的改变涉及到stop/start the world来resize数组P的大小。
gfree和grunnable从sched中移到P中。这样就解决了前面的单个全局锁保护用有goroutine的问题,由于goroutine现在被分到每个P中,它们是P局部的goroutine,因此P只管去操作自己的goroutine就行了,不会与其它P上的goroutine冲突。全局的grunnable队列也仍然是存在的,只有在P去访问全局grunnable队列时才涉及到加锁操作。mcache从M中移到P中。不过当前还不彻底,在M中还是保留着mcache域的。
加入了P后,sched.atomic也从Sched结构体中去掉了。
当一个新的G创建或者现有的G变成runnable,它将一个runnable的goroutine推到当前的P。当P完成执行G,它将G从自己的runnable goroutine中pop出去。如果链为空,P会随机从其它P中窃取一半的可运行的goroutine。
当M创建一个新G的时候,必须保证有另一个M来执行这个G。类似的,当一个M进入到系统调用时,必须保证有另一个M来执行G的代码。
2层自旋:关联了P的处于idle状态的的M自旋寻找新的G;没有关联P的M自旋等待可用的P。最多有GOMAXPROCS个自旋的M。只要有第二类M时第一类M就不会阻塞。